我的 MySQL 随笔
Last updated on December 18, 2023 am
- 基础篇
- 架构篇
- 存储引擎
- 日志管理
- SQL调优
- 索引
- 锁
- 事务
- 高可用/性能
- 运维
MySQL形象八股文,不形象你打我
首先,自我洗脑:MySQL不难!MySQL不难!MySQL不难!!!
学习 MySQL 之前,我们先问问自己什么是 MySQL ?他是一个关系型数据库(R-DBMS:relational database manage system),顾名思义就是用于存放数据的。
为什么大家都学 MySQL ,有什么优点?用我的屁股想一想,首先肯定稳定、好用、免费,再加其他的优点,所以就被广泛使用了。
🆗,那我们就话不多说,下面围绕 MySQL 就是一个存放数据的房子的理念(什么?放数据的房子?那么就是快递驿站吗),浅析 MySQL!
基础篇
Q:什么是数据库第一二三范式?
A:
- 第一范式:又称专一范式,字段不能再拆分;
- 第二范式:又称 MySQL 家规,必须完全依赖顺从主键,若有与主键无关字段者,设置为联合主键;
- 第三范式:又称恋爱脑范式,遵守家规,远离小三。

一般来说,“小企”这个渣男(也可能不止小企)在日常开发中都是违反范式家规标准的,要为了性能,通过一些冗余的数据,空间换时间。
Q:MySQL 有几种字段类型?
A:字段类型大致可以分为三类:数值类型、字符类型、时间类型
数值类型:
整数类型:微小TYNYINT、小SMALLINT、中等MEDIUMINT、INT、大整型BIGINT;
小数类型:FLOAT、DUBBLE、DECIMAL、NUMERIC
字符类型:(还有好几种)
CHAR
VARCHAR
BINARY
VARBINARY
BLOB
- 二进制大对象类型,用于存储二进制数据(如文档、图像、音频等),有两个分支,小TINYBLOB和长LONGBLOB
TEXT
- 文本类型,不许预设长度,可根据需要动态划分空间。也分为 TINYTEXT 和 LONGTEXT,以适应不同大小的文本数据
ENUM
- 枚举类型,限制了字段存储的值
SET
- 集合类型,不可重复
日期/时间类型
- DATE
- TIME
- DATETIME
- TIMESTAMP
Q:CHAR 和 VARCHAR 字符类型的区别?
A:
char长度固定,所以存取速度快,甚至快varchar一半;如果长度没有达到预设值,用空格补充。因为定长,所以浪费一些空间,属于空间换时间。最多可存255个字符;varchar字符长度可变,所以不浪费空间,属于时间换空间。最多可存放65532个字符串,至于为什么是65532,那就需要看相关存储引擎InnoDB的知识了。
Q:说一说两个时间类型的区别
A:
- 时间起始范围不同,
TIMESTAMP为1970-2028,datetime为1000-9999 - 存储空间不同,
TIMESTAMP存储空间为4字节,DATETIME存储空间为8字节 - 时区,
TIMESTAMP存储时间依赖于时区显示,DATETIME存储时间与时区无关 - 默认值,
TIMESTAMP不为空,后者为空
Q:什么类型可以用于存储二进制数据?
A:blob,Blob常常是数据库中用来存储二进制文件的字段类型。通常用于存储大量的数据,例如音频、视频、图片等文件,由于它们的大小,必须使用特殊的方式来处理(例如:上传、下载或者存放到一个数据库)。
Q:怎么存储
emoji表情?
A:
Q:你了解 SQL 的执行流程吗?
A:为了更加直观,借用三元表达式的语法来描述一条 SQL 执行的流程。
- 首先检查 SQL 是否有执行的权限? 查询结果缓存 :返回报错信息;
- 是否有缓存? 直接返回结果 :检查 SQL 是否有语法错误;
- 语法正确? MySQL 的服务器对语句进行优化,确定执行方案 :
- 确定方案?调用数据库引擎接口,执行方案,返回执行结果。
Q:什么是 DDL 与 DML ?
A:是 DBMS 中的不同类型的语言指令集。
- DDL:database definition language,定义或修改数据库结构的命令,例如:CREAT、ALTER、DROP、TRUNCATE(截断,命令用于快速删除表中的所有数据但不删除表本身。)
- DML:database manipulation language,用于操作数据库中的数据的命令,例如CURD
架构篇
首先,收起你自认为架构篇很难理解的想法,我们还是从 MySQL 是一个房子入手。
Q:你是怎么理解 MySQL 的架构的?
A:MySQL 就相当于一个档案室,存放不同的档案,一个数据库好用,肯定有原因,架构也就是构成。那么一个快递驿站肯定包括下面这三部分:
- 快递驿站APP–客户端(与用户交互的关键)
- 工作人员–存储引擎(我 MySQL 学的不好,我猜应该是与存储规则相关的)
- 快递货架–服务层(堆放数据,索引数据)
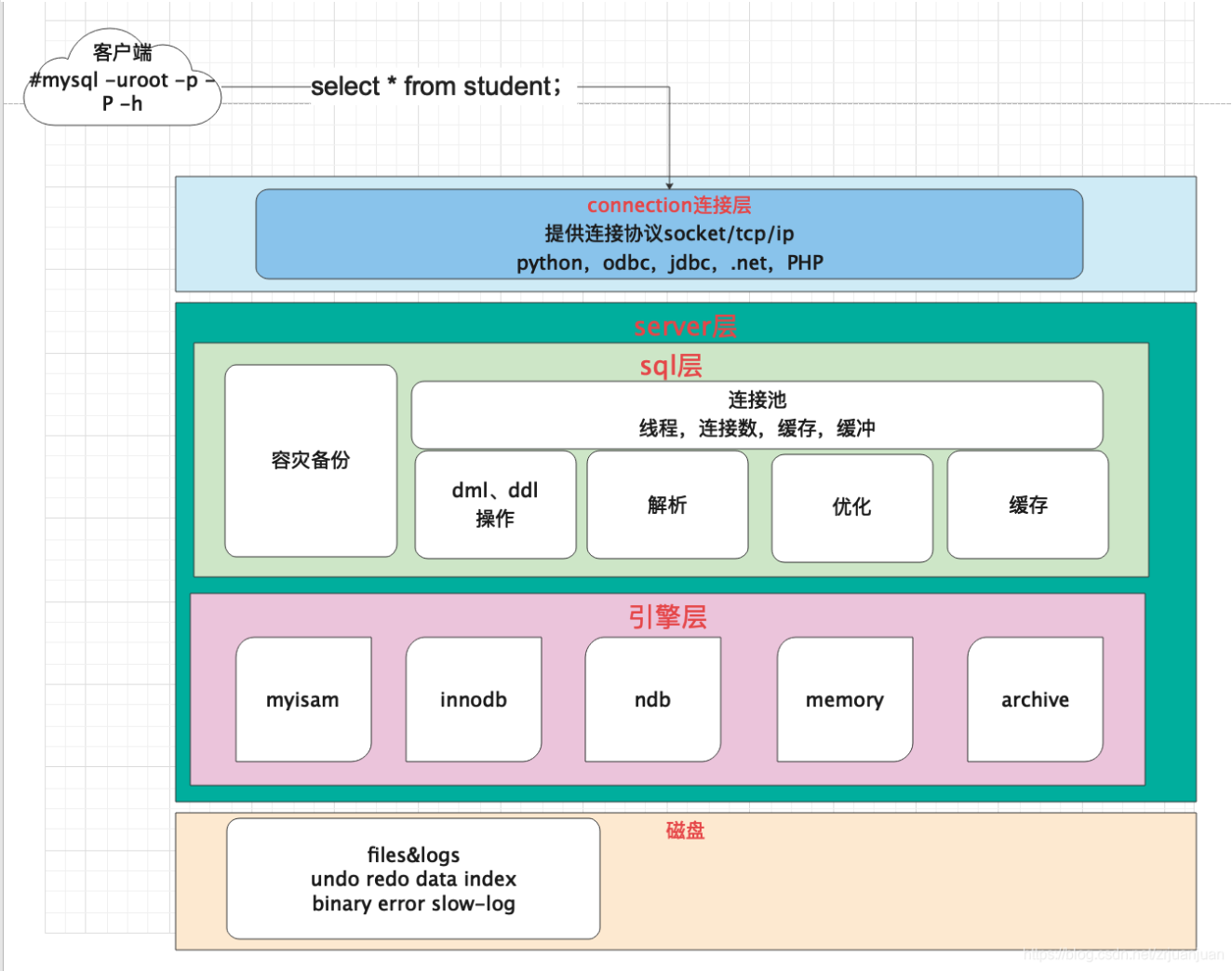
{{{{{{待画图!!!}}}}}}
MySQL 逻辑架构图主要分为三层:客户端、存储引擎、服务层
- 客户端层:这是与 MySQL 服务器交互的接口,它提供了用户与服务器进行通信的手段。客户端层处理连接请求、处理查询请求、认证用户权限以及执行与服务器之间的通信。此外,这一层还负责处理与服务相关的各种任务,例如管理连接、处理错误、诊断和调试等。
- Server 层:这一层是 MySQL 的核心,它包含了大多数 MySQL 的服务功能。这包括解析查询语句、分析查询计划、优化查询计划以及执行查询计划等。此外,Server 层还负责处理内置函数,如日期、时间、数学和加密函数等。对于跨存储引擎的功能,如存储过程、触发器和视图等,也都在这一层实现。这些功能对于整个数据库系统来说是至关重要的。
- 存储引擎层:这一层负责数据的存储和提取。存储引擎负责与底层操作系统交互,管理数据的存储位置、文件格式和索引等。不同的存储引擎具有不同的特点和性能,可以根据应用的需求选择适合的存储引擎。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。存储引擎通过 API 与 Server 层进行通信,这些接口屏蔽了不同存储引擎之间的差异,使得上层的应用程序可以透明地访问底层的数据存储方式。
Q:数据库调优,你是怎么做的
A:以下回答来自文心一言,待优化,回答要结合MySQL的架构以及存储引擎来说,以及自己的见解
数据库调优的方法有很多,以下是一些常见的调优方法:
- 定期优化重建数据库:定期对数据库进行优化和重建,可以消除数据库中的碎片和冗余数据,提高数据库的性能和稳定性。
- 减少磁盘写入操作:通过使用缓存技术、优化数据插入和更新操作、避免频繁的磁盘操作等手段,可以减少磁盘的写入操作,提高数据库的性能。
- 合理使用索引:索引是提高查询速度的重要手段,通过添加合适的索引可以加速查询操作。需要根据查询语句和表结构来确定需要添加的索引。
- 优化SQL语句:通过优化SQL语句,可以减少数据库的负载和提高查询效率。例如,避免使用SELECT * 语句,只查询需要的数据字段;避免在查询中使用复杂的子查询和连接查询等。
- 调整数据库参数:根据实际需求和性能测试结果,调整数据库的参数可以提高数据库的性能和响应速度。
- 使用存储过程和触发器:存储过程和触发器可以减少数据库的负载和提高数据处理效率。通过将常用的数据处理逻辑封装到存储过程和触发器中,可以减少对数据库的频繁操作。
- 数据库分区:对于大型数据库,可以采用分区技术将数据分散到不同的磁盘上,提高I/O处理能力和并发性能。
- 使用RAID技术:RAID技术可以提供高性能、高可靠性和高容错的存储系统,通过将数据分散到多个磁盘上,可以提高I/O处理能力和数据安全性。
- 使用缓存技术:缓存技术可以减少磁盘访问次数和提高数据处理速度。例如,使用内存缓存来存储经常访问的数据,减少对磁盘的访问次数。
- 定期备份数据:定期备份数据可以防止数据丢失和灾难性故障,同时也可以提高数据处理效率和安全性。
这些方法可以根据实际情况选择使用,但需要注意的是,数据库调优是一个复杂的过程,需要综合考虑系统硬件、应用程序和数据等方面的因素。因此,在进行数据库调优时,建议根据实际情况进行测试和评估,以确保达到最佳的效果。
Q:你知道三种存储引擎的区别吗?
A:
| 功能 | MlSAM | MEMORY | InnoDB |
|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB |
| 支持事务 | No | No | Yes |
| 支持全文索引 | Yes | No | Yes |
| 支持树索引 | Yes | Yes | Yes |
| 支持哈希索引 | No | Yes | Yes |
| 支持数据缓存 | No | N/A | Yes |
| 支持外键 | No | No | Yes |
怎么选择存储引擎的使用?
- 想用事务安全,并要求实现并发控制,用InnoDB
- 主要用来查询与插入记录,用MyISAM
- 临时存放数据,不考虑安全,用MEMORY
tips:存储引擎是基于数据表的,所以一个数据库的多个表可以根据实际业务,来使用不同的存储引擎,以此提高整个数据库的性能。
| 区别 | MyISAM | InnoDB |
|---|---|---|
| 存储结构 | 每个表存储成3个文件:表定义文件(.frm)数据文件(.MYD)索引文件(.MYI) | 所有表存放于同一数据文件,也可能多个文件或者独立的表空间文件,表的大小一般为2G |
| 事务 | 不支持 | 支持 |
| 最小锁粒度 | 表级锁,更新会锁表,导致其他查询与插入阻塞 | 行级锁 |
| 索引类型 | 非聚簇索引,B树 | 聚簇索引,B+树 |
| 主键 | 可无 | 如未设置,自动生成(用户不可见) |
| 外键 | 不支持 | 支持 |
| 表行数 | 存有缓存,直接取出 | 需要遍历整个表 |
🆗架构篇就到这里,有没发现,似乎MySQL的基础架构也就这回事,也没啥难点。最后强调一点,当我们试图学会一门知识的时候,不要机械记忆,重要的是融会贯通(内心OS:啥子贯通?不就是理论翻译成人话吗?),找到适合自己记忆的方法。